MPLS中VPLS的转发平面机制
用户需要配置的本地端口是PE上每个VPLS的成员。每个PE为每个VPLS维护一个单独的转发表。对于每个VPLS,参与的PE与伪线完全耦合。全网状网络的优势在于,PE不必运行生成树算法即可消除环路的可能性。首先讨论如何将单播以太网帧转发到目的地,然后讨论广播和多播帧的处理。
转发单播帧
X网络的主机A,MAC地址为A,J的MAC地址为J。A将源MAC地址A的帧发送给目标MAC地址J。假设PE1不知道J的MAC。PE1将泛洪除接收端口外的所有其它端口。这意味泛洪到CE2的本地端口,伪线上到PE2和PE3,一个到PE2,一个到PE3。这可能会浪费带宽,因为重复的有效负载可能沿同一链路传播。一些实现允许PE用P2MP LSP将帧泛洪到VPLS实例的其它PE。
PE2和PE3通过帧到达的伪线知道传入帧属于客户X的VPLS。PE2和PE3分别在对应于客户X的VPLS转发表中对目标MAC进行查找。如果不知道J的位置,将面向CE4和CE5的本地端口泛洪,但不会泛洪到其它PE。这种水平分割方案确保不会发生转发环路。同样,PE3将帧发送到CE7。
每个PE均获知A的位置。PE1在转发表放置一个条目面向CE1的端口。PE2和PE3也放置一个条目,和伪线建立关联。现在J开始向A发送帧,PE2有一个指向A的转发表。当PE1收到帧,了解到J的帧并相应更新转发表,可不再需要泛洪。假设一段时间后,PE1学到客户X的所有MAC。对应的转发表如下。
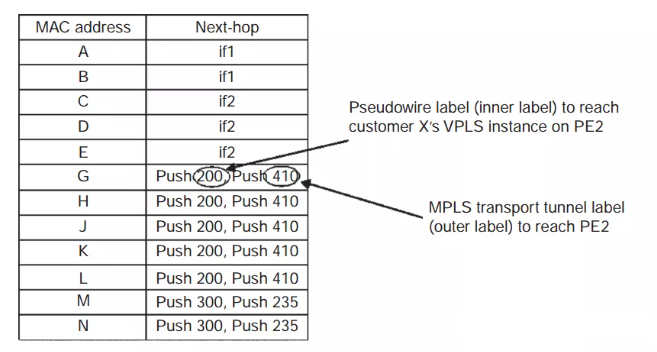
可以看出,某些条目对应本地接口,某些指向远程PE。后一种转发表显示伪线标签和传输标签。MAC始终是学习的,VPLS实现用于MAC老化的机制,可从转发表中删除陈旧的MAC。一种实现可选择删除某个分钟未使用的MAC。此外,如果表的大小达到限制,可实现删除最长时间未用的条目。
广播和多播帧
PE1收到主机B发送的广播帧,该帧必须转发到X的所有站点。PE1将帧泛洪到PE2和PE3,以及CE2。PE2和PE3依次泛洪到属于X的CE。在某些实现,入口PE执行入口复制,将组播和广播帧发送到VPLS实例中其它PE,就像处理未知单播帧一样。通过用P2MP LSP承载BUM流量,避免了入口复制造成的带宽浪费。如果在VPLS实例发送大量的多播流量,则可以节省带宽。
另一种优化是IGMP和PIM,这与使用入口复制或组播树来转发组播流量无关。IGMP侦听的原理类似交换机使用的原理。就像其它在VPLS客户站点间传输的第3层协议一样,IGMP和PIM数据包只是“负载”到PE,在提供商部分透明传输,因为VPLS是第2层服务,因此提供商和VPLS客户间没有第3层协议交互。但PE可检查“窥探”IGMP和PIM数据包的内容,以便确定需要接收指定多播组或指定源。如果出口PE后面有感兴趣的接收者,则向CE发送多播流量。仅将多播帧发送到感兴趣的接收PE。
以上就是MPLS中VPLS的转发平面机制的介绍,
如果你还有其他问题,欢迎进行咨询探讨,希望我们的专业的解决方案,可以解决你目前遇到的这些问题。
上一篇:MPLS中VPLS的控制平面机制
下一篇:MPLS中的VPLS机制